K-Fold Cross Validation 딥러닝 (Keras, Image Data Generator)
캐글 머신러닝 문제들을 풀면서 K-Fold Cross Validation (교차검증)를 자주 사용했었는데, 이번에 딥러닝에서 쓸 일이 있어서 Keras 에서 Image Data Generator와 함께 사용해봤다.
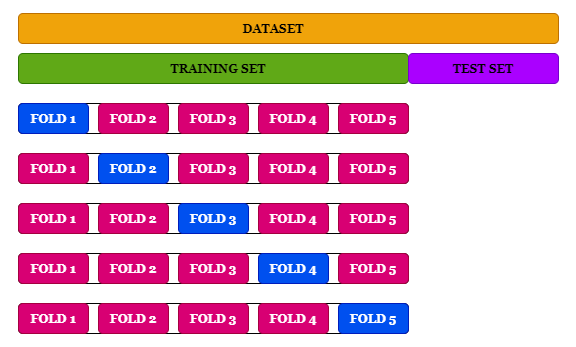
교차검증 소개 글 (여러 교차검증 종류도 소개가 잘 되어있다~) : davinci-ai.tistory.com/18
머신러닝 (5) - Cross Validation(교차검증)
Writer: Harim Kang 머신러닝 - 5. End-to-End Machine Learning Project (4) 해당 포스팅은 머신러닝의 교과서라고 불리는 Hands-On Machine Learning with Scikit-Learn & Tensor flow 책을 학습하며 정리하..
davinci-ai.tistory.com
이진분류 문제에서 사용했는데, 데이터를 타켓값(y)의 기준으로 봤을 때 분포가 고르지 않아서 StratifiedKFold 를 사용했다.
StratifiedKFold는 KFold의 변형된 반복자로 각각 비율이 다른 클래스의 비율을 유지하면서 훈련과 테스트 세트를 분류하도록 해준다. (출처: https://davinci-ai.tistory.com/18 [DAVINCI - AI])
<예시 코드 from 사이킷런 공식 User Guide>
>>> import numpy as np
>>> from sklearn.model_selection import StratifiedKFold
>>> X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]])
>>> y = np.array([0, 0, 1, 1])
>>> skf = StratifiedKFold(n_splits=2)
>>> skf.get_n_splits(X, y)
2
>>> print(skf)
StratifiedKFold(n_splits=2, random_state=None, shuffle=False)
>>> for train_index, test_index in skf.split(X, y):
... print("TRAIN:", train_index, "TEST:", test_index)
... X_train, X_test = X[train_index], X[test_index]
... y_train, y_test = y[train_index], y[test_index]
TRAIN: [1 3] TEST: [0 2]
TRAIN: [0 2] TEST: [1 3]
<코드>
1. StratifiedKFold, ImageDataGenerator 선언
Train data는 DataFrame 형식으로 만들었다 -> Column은 파일 이름이 포함된 "file" 칼럼과 라벨값(Y)이 포함된 "label" 값이 있음
train_data = pd.read_csv('data.csv')
Y = train_data[['label']]
skf = StratifiedKFold(n_splits=5, random_state=42, shuffle=True)
# train 용
idg = ImageDataGenerator(rescale=1./255,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
# validation 용
idg2 = ImageDataGenerator(rescale=1./255,
)
2.
주의해야할 점은 딥러닝은 머신러닝과 다르게 모델 선언을 for 문 밖에서 해주면 그 전 학습을 계속 이어서 해주기 때문에 모델 선언을 for 문 안에서 해줘야하고, backend.clear_session()도 해줘야한다.
tf.keras.backend.clear_session
Keras manages a global state, which it uses to implement the Functional model-building API and to uniquify autogenerated layer names.
If you are creating many models in a loop, this global state will consume an increasing amount of memory over time, and you may want to clear it. Calling clear_session() releases the global state: this helps avoid clutter from old models and layers, especially when memory is limited.
VALIDATION_ACCURACY = []
VALIDAITON_LOSS = []
val_acc = 0
fold_var = 1 # weight 나 모델 저장용
for train_index, val_index in skf.split(train_data, train_data['label']): # Y의 분포 기준으로 나눔
training_data = train_data.iloc[train_index] # train data
validation_data = train_data.iloc[val_index] # valid data
train_data_generator = idg.flow_from_dataframe(training_data, directory='이미지 경로',
x_col="file", y_col="label",
class_mode="categorical", shuffle=True) # Softmax
valid_data_generator = idg2.flow_from_dataframe(validation_data, directory='이미지 경로',
x_col="file", y_col="label",
class_mode="categorical", shuffle=True)
print(len(train_data_generator))
print(len(valid_data_generator))
# CREATE NEW MODEL
model = Sequential()
# EfficientNet 사용
model.add(EfficientNetB0(include_top=False, pooling='avg', weights='imagenet'))
model.add(Dense(2, activation='softmax'))
model.compile(optimizer = 'adam', loss = tf.keras.losses.categorical_crossentropy, metrics = ['acc'])
# CREATE CALLBACKS
checkpoint_path = "weight 저장할 경로" + str(fold_var) + ".ckpt"
modelcheckpoint = ModelCheckpoint(checkpoint_path, monitor='val_loss', mode='min', save_best_only=True,
save_weights_only=True)
# learning rate scheduler
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=20, verbose=1)
earlystopping = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=20)
callbacks_list = [modelcheckpoint,earlystopping,reduce_lr]
# FIT THE MODEL
history = model.fit(train_data_generator,
epochs=100,
callbacks=callbacks_list,
validation_data=valid_data_generator)
# 모델 저장
model.load_weights(checkpoint_path)
model_path = "모델 저장할 경로" + str(fold_var) + ".h5"
model.save(model_path)
results = model.evaluate(valid_data_generator)
results = dict(zip(model.metrics_names, results))
VALIDATION_ACCURACY.append(results['acc'])
VALIDAITON_LOSS.append(results['loss'])
tf.keras.backend.clear_session() ########
fold_var += 1
val_acc += results['acc']/5 # 평균 Acc
print(val_acc)
참고 자료 :
medium.com/the-owl/k-fold-cross-validation-in-keras-3ec4a3a00538
'AI > Self-Study' 카테고리의 다른 글
| Keras : ImageDataGenerator 대신에 tf.data로 빠르게 학습하기 1 (0) | 2021.04.12 |
|---|---|
| Keras에서 predict와 predict_generator 가 다른 값을 내는 경우 (Image Data Generator) (0) | 2021.04.09 |
| ArcFace - ResNetFace / SE-LResNet50E-IR (2) | 2021.04.09 |
| tensorflow 모델 학습 시간 보기 (0) | 2021.01.14 |
| EfficientNet 모델 구조 (1) | 2021.01.12 |