[1강] Introduction to Convolutional Neural Networks for Visual Recognition
이 강의는 Computer Vision (컴퓨터 비전)에 관한 강의다.
소개
1. Computer Vision 이란? 말 그대로, Visual data (시각 데이터)에 대한 연구다.
2. 왜 이 공부를 해야 할까? 지난 몇 년간 시각 데이터의 양이 어마어마하게 많아졌기 때문이다! 우리 옆에는 카메라가 1개 또는 3개까지 달린 스마트폰이 항상 존재한다. 이런 센서들을 통해 엄청난 양의 시각 데이터가 만들어지는 것이다.
-
CISCO는 2015년 연구에서 2017년에는 인터넷 트래픽의 80% 이상이 비디오일 것이라고 예상했다 (이미지와 같은 다른 타입의 시각데이터를 빼고 오직 비디오만 고려). 그러므로 인터넷에 돌아다니는 대부분의 데이터는 시각 데이터다. 우리는 이 데이터를 이해하고 활용할 수 있는 알고리즘을 만들 필요가 있다.
-
유튜브의 통계에 따르면, 매 초마다 유튜브에는 5시간 분량의 비디오가 올라온다. 우리가 지금 3초를 세는 동안 유튜브에는 새로운 15시간 분량의 비디오가 올라와있다. 유튜브가 아무리 많은 직원을 뽑아도 직원들이 모든 비디오를 모디터링 할 수는 없다. 비디오를 분류하고, 유저들에게 연관 비디오를 추천해주고, 광고를 붙여 돈을 벌려면 자동으로 그 많은 비디오들을 이해할 수 있는 기술이 필수다.
근데 문제는... 시각 데이터는 이해하기 어렵다.
물리학의 Dark Matter와 비슷한 개념인데, (우주를 구성하고 있는 물질의 구성은 우리가 익히 알고 있는 4%의 원자 물질과 검출하기 어렵지만 분명 존재하는 걸로 확신하는 96%의 물질로 이루어져 있다. 검출하기 어렵다는 의미에서 Dark라는 표현을 사용한다고 한다) 시각데이터는 인터넷에 돌아다니는 대부분의 비트를 구성하고 있지만, 알고리즘이 정확히 무엇이 모든 시각 데이터를 구성하는지 이해하는 것은 매우 어렵다.
컴퓨터 비전의 역사
1. 생물학적 비전
Computer Vision의 역사는 5억 4300만 년 전으로 거슬러 올라간다. 그전에 지구는 거의 물로 이루어져 있었고, 적은 종의 고대 생물들이 물에서 떠돌아다녔다. 먹이를 찾아 먹지 않고, 음식이 지나가면 먹는 수동적인 삶이었다. 하지만 천만년이라는 짧은 시간 동안 생물의 종이 갑자기 폭발적으로 늘어난 시기가 있었다. 생물학자들은 이것을 캄브리아기 폭발 (Cambrian explosion 또는 evolution's Big Bang)라고 불렀다. 이 현상의 이유로 오스트레일리아의 동물학자가 가장 설득력 있는 이론을 내놨는데, 이 시기에 동물에게 처음 시각이 생겼다는 주장이었다. 시각은 동물들이 능동적으로 살게 했다 - 세상은 포식자와 먹잇감으로 나뉘었고, 동물들은 생존을 위해 빠르게 진화했다. 시각은 동물들에게, 특히 지능이 있는 동물들에게 (인간) 매우 중요한 감각기관으로 발전했다.
2. 기계적 비전
1600년대 르네상스 시대에 핀홀 상의 방법론 (pinhole camera theories)기반으로 발명된 카메라 옵스큐라(camera obscura)는 오늘날 사용하는 카메라의 조상이자, 사진 이미지가 만들어지는 원리다. 이는 초기에 동물의 눈가 비슷한 점이 있는데, 작은 구멍이 빛을 모으고, 반대편 카메라 안쪽은 밖에 있는 대상의 거꾸로 된 상을 비치는 방식으로 정보를 모으고 이미지를 투사해주는 점이다. 카메라는 발전하면서 우리에게 가장 인기 있고, 자주 쓰이는 센서가 되었다.
그동안에 생물학자들은 시각적으로 무엇을 보고 인식하는 방법을 연구하기 시작했다. Hubel과 Wiesel이 50년대와 60년대 초에 전기생리학 (electrophysiology)에서 연구했던 내용은 많은 연구들 중에서도 가장 영향력 있는 연구로 뽑힌다. 그들은 영장류와 포유류들이 시각적으로 어떤 방법으로 이미지를 처리하는지 고양이 뇌를 이용해 연구했는데, 고양이 뇌 뒤쪽인 일차 시각 피질 (primary visual cortex)부분에 전극을 꽂고, 그쪽에 위치한 뉴런들이 흥분하여 반응하게 하는 자극은 무엇인지 실험했다. 그 결과, 일차 시각 피질 부분에는 다양한 세포가 존재하지만, 가장 중요한 세포 중 하나는 어떤 방향으로 이동할 때 방향의 가장자리들 (oriented edges)에 반응하는 단순 세포들이라는 것을 알게 되었다. 더 복잡하고 큰 세포들도 많지만, 이미지 처리는 방향의 가장자리라는 시각 세계의 단순한 구조에서 시작해 - 정보가 시각적 처리 경로를 따라 이동하면서 - 뇌는 복잡한 시각 세계를 인식할 수 있을 때까지 시각적 정보의 복잡성을 증가시키는 방식으로 이뤄져 있다는 것을 발견했다.
3. 컴퓨터 비전
컴퓨터 비전 또한 60년대 초에 시작됐다. Block World는 Larry Roberts (아마도 컴퓨터 비전에 대한 최초의 박사학위 논문을 작성한 사람)가 출판한 일련의 작업인데, 시각 세계를 간단한 기하학적 형태로 단순화시키고, 그것을 다시 인식하고 그 형상으로 재구성할 수 있는 것이 목표였다.
1966년에는 현재 유명한 "The Summer Vision Project"라고 불리는 MIT의 summer project가 있었는데, 이 프로젝트의 목표는 "attempt to use our summer workers effectively in a construction of a significant part of a visual system" (시각 체계의 중요한 부분을 구현하는 데에 프로젝트 참가자들을 효율적으로 이용하려는 시도)였다. 다시 말해, 그들은 그 여름 동안 대부분의 시각 체계를 구현하겠다는 야심 찬 목표를 가지고 있었다. 50년이 지난 지금 , 컴퓨터 비전 분야는 한 여름 프로젝트에서 수천 명의 전 세계 연구자들이 연구하는 분야로 커졌지만, 여전히 비전의 가장 근본적인 문제들을 연구하고 있다.
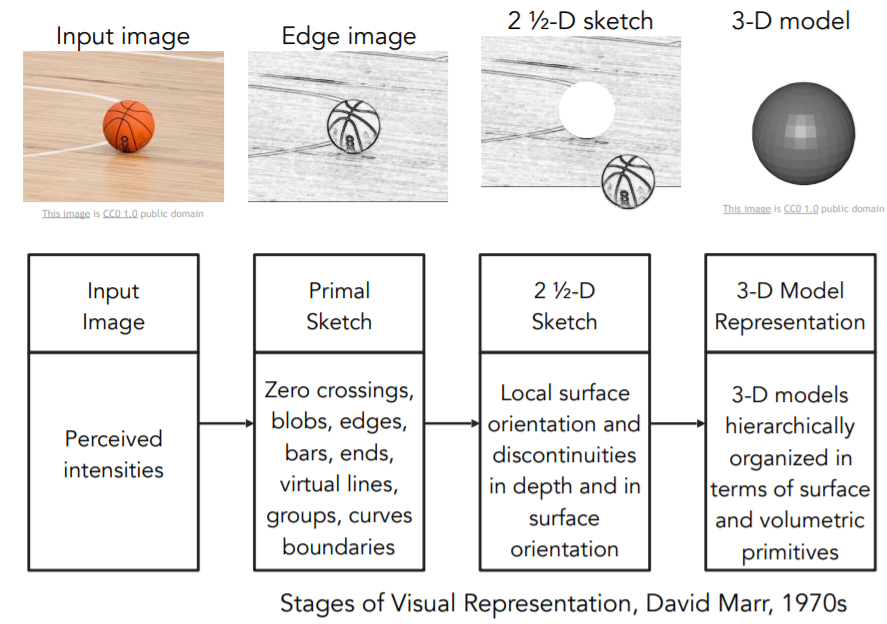
David Marr는 MIT의 비전 과학자였던 인물로 70년대 말에 그가 비전을 무엇이라 생각하는지, 컴퓨터 비전이 어떻게 나아가야 하는지, 어떻게 컴퓨터가 비전 세계를 인식할 수 있도록 하는 알고리즘을 개발해야 하는지에 대한 영향력 있는 책을 썼다. 그는 책에서 이미지를 가지고 최종적인 완전한 3D 표현까지 도달하기 위해서는 몇 단계의 과정을 거쳐야만 한다고 주장했는데, 첫 번째 단계는 그가 "primal sketch"라고 부르는 것이었다. 이 단계는 주로 가장자리/모서리(edges), 막대(bars), 끝(ends), 가상의 선(virtual lines), 커브(curves), 경계(boundaries)가 해당되고, 신경과학자들에게 영감을 받은 것이다 (Hubel과 Wiesel의 시각적 처리의 초기 단계는 가장자리와 같은 간단한 구조와 많은 관련이 있다는 주장). 다음 단계는 "two-and-a-half-D sketch"로 표면(surfaces) 정보, 깊이 정보, 레이어, 시각 장면을 구성하는 불연속 점과 같은 것들을 종합한다. 궁극적으로, 모든 것을 한데 모아서 표면(surface)부터 volumetric primives(체적 초기단계) 등.. 계층적으로 구성된 최종적인 3D 모델을 만들어 낸다. 이 방식은 비전이 무엇인가에 대한 이상적인 사고방식으로 수십 년간 컴퓨터 비전 분야를 지배했고, 입문자가 어떻게 시각정보를 분석할 수 있을까 생각해볼 수 있는 직관적인 방법이다.
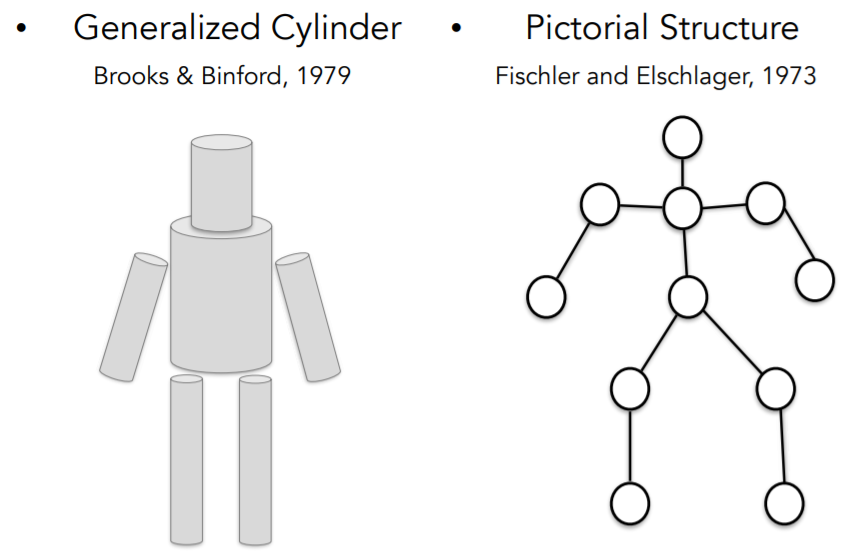
70년대에 사람들은 어떻게 block world (블록 세계)를 뛰어넘어서 실제 세계를 인식하고 표현할 수 있을까?라는 질문을 하기 시작했고, 컴퓨터 과학자들은 어떻게 물체를 인식하고 표현할 수 있을지 고민하기 시작했다. 이 때 Stanford와 SRI에서 과학자들이 서로 비슷한 아이디어를 제안했는데, "generalized cylinder"와 "pictorial structure"였다. 둘의 개념은 모든 객체는 단순한 기하학적 원형으로 구성되어 있다는 것이다. 사람을 원통 모양을 조합해서 만들던가, 주요 부위/관절로 표현할 수도 있다. 이렇게 단순한 모양과 기하학적인 구성을 이용해서 복잡한 객체를 단순화시키는 방법은 수년간 다른 연구에 많은 영향을 미쳤다.
80년대에 David Lowe 또한 단순한 구조로 실제 세계를 재구성하고 인식할 수 있을지 고민했는데, 그의 연구에서 면도기를 선(lines), 모서리(edges),직선(straight lines)과 이의 조합을 이용해서 구성함으로써 면도기를 인식하려고 노력했다.

60년부터 80년대까지 계속해서 컴퓨터 비전이 하는 일에 관한 연구가 이뤘졌지만, 객체 인식 문제를 해결하긴 어려웠다. 위 사례들은 모두 야망 넘치는 시도였지만, 아주 단순한 수준의 예시나, 몇 개의 예시에만 적용되었고, 현실 세계에서 사용할 수 있냐를 기준으로 보면 진척도가 낮았다고 볼 수 있다. 그래서 사람들은 객체 인식이 너무 어렵다면, 이미지를 가져와 픽셀을 의미 있는 영역으로 그룹화하는 작업인 이미지 분할 (image segmentation)부터 먼저 해보자는 생각을 했다. 픽셀을 모아놔도 그게 사람이라는 걸 인식할 수 없을지도 모르지만, 적어도 배경에서 사람에 해당되는 모든 픽셀들은 추출할 수 있다는 것이 이미지 분할이다.
Image Segmentation
초기에 Berkeley 대학의 Jitendra Malik 교수와 Jianbo Shi 학생이 이미지 분할 문제를 해결하기 위해서 그래프 이론을 사용했다.

얼굴 인식은 컴퓨터 비전에서 발전 속도가 빨랐던 분야였다. 사람들에게 가장 관심의 대상이었던 얼굴 인식 분야에서 1999년에서 2000년 사이에는 기계 학습 기법, 특히, 통계적 기계 학습 기법이 탄력을 받기 시작했다. "Support Vector Machine", "Boosting", "Graphical models", 그리고 초기 "Neural Network" 등이 있었다. 그 중 가장 큰 기여를 한 연구는 Paul Viola와 Michael Jones의 AdaBoost 알고리즘을 사용한 실시간 얼굴인식이었다. 컴퓨터가 매우 느렸던 2001년이었음에도 불구하고 실시간과 가깝게(near-real-time) 얼굴을 인식할 수 있었고, 논문 발표 5년이 지난 2006년에 Fujifilm이 실시간 얼굴인식을 지원하는 최초의 디지털카메라를 선보였다. 이는 기초 과학 연구에서 현실세계 응용으로 전환이 매우 빠른 사례였다.

90년대 후반부터 2010년도까지는 특징기반 물체인식이 인기였다. David Lowe의 SIFT features는 물체 전체를 매칭시키는 것이다. 정지 표지판 두 개를 매칭 시키는 일은 카메라 각도, 조명, 그리고 물체의 본질적인 변화 등 모든 종류의 변화가 있을 수 있기 때문에 어렵다. 하지만, David Lowe는 물체의 특징 중 일부는 다양한 변화에 조금 더 강인하고 불변하다는 점을 발견했다. 물체 인식은 물체에서 중요한 특징을 찾아내는 것으로 시작해 그 후, 비슷한 물체와 특징을 매칭 시켜본다. 그의 논문을 보면, 정지 표지판에서 수십 개의 SIFT 특징이 식별되고, 다른 정지 표지판의의 SIFT 형상과 매칭(일치)된다.

이미지의 특징을 사용하면서 컴퓨터 비전은 한번 더 도약하면서 전체 장면을 인식하기 시작한다. Spatial Pyramid Matching라는 알고리즘 예시가 있는데, 이 알고리즘의 개념은 이미지들의 특징들이 장면이 어떤 종류인지 단서를 줄 수 있다는 것이다 (장면이 풍경인지, 부엌인지, 고속도로인지 등...). 이 연구는 이미지 내의 여러 부분과 여러 해상도에서
추출한 특징을 하나의 특징 기술자로 표현하고 Support Vector Algorithm을 적용한다. 이런 방식의 비슷한 연구들은 사람 인식에도 탄력을 줬다.

사람인식과 관련된 연구들은 어떻게 해야 사람의 몸을 현실적으로 인식하고 이미지로 모델링할 수 있을지에 관련된 연구였다. "Histogram Of Gradients" 라는 연구와 "Deformable Part Models"이라는 연구가 있다. 60,70,80년대를 거치고 21세기로 오면서 인터넷과 디지털카메라의 발전은 컴퓨터 비전을 공부하기 위한 더 좋은 실험 데이터를 만들어 낼 수 있게 했다. 2000년대 초에 일궈낸 결과물 중 하나는 바로 컴퓨터 비전 분야가 앞으로 풀어야 할 문제가 무엇인지의 정의를 냈다는 것인데, 그것이 풀어야 할 유일한 문제는 아니지만 인식 측면에서 이것은 매우 중요한 문제였다. 바로 "객체인식"이다. 지금까지 계속 객체인식에 대해 이야기 해왔지만, 2000년대 초 우리는 객체인식의 과정을 측정할 수 있게 해주는 Benchmark Dataset를 갖기 시작했다. 가장 영향력있는 benchmark dataset 중 하나는 PASCAL Visual Object Challenge 였다.
'AI > CS231n' 카테고리의 다른 글
| [5강] Convolutional Neural Networks (0) | 2020.11.07 |
|---|---|
| [4강] Introduction to Neural Networks (0) | 2020.10.31 |
| [3강] Loss Functions and Optimization (0) | 2020.10.30 |
| [2강] Image Classification (0) | 2020.10.17 |
| [0강] 딥러닝 기초 이론 스터디 - CS231n (0) | 2020.10.10 |