[5강] Convolutional Neural Networks
이번에는 Convolutional Layer에 대해 배울 것이다.
먼저 CNN의 역사를 알아보자.
<간단한 역사>
1957년 Frank Rosenblatt가 Mark I Perceptron machine 을 개발했다. 이 기계는 perceptron이라고 불리는 알고리즘을 구현한 최초의 기계인데, 이 알고리즘은 우리가 배운 Wx + b 와 유사한 함수를 사용하고 가중치 W를 update하는backprop과 유사한 update rule이 존재했다 하지만 출력 값이 0 또는 1이다. 그리고 1960년에는 Widrow와 Hoff가 최초의 Multilayer Perceptron Network였던 Adaline and Madaline을 개발했다. Neural network layers와 비슷한 모양을 했지만 backprob가튼 학습 알고리즘이 없었다. 최초의 Backporp은 1986에 Rumelhart가 제안했다. 이때 최초로 network를 학습시키는 것에 관한 개념이 정립되기 시작했다. 2000년대가 된 후, Geoff Hinton 과 Ruslan Salakhutdinov가 2006년 논문에서 DNN (deep neural network)의 학습가능성과 DNN이 실제로 효과적이라는 것을 보여줬지만 현재 알려진 neural network iteration(반복)은 아니였다.
실제로 neural network의 광풍(모델의 좋은 성능) 이 불기 시작한 때는 2012년이었다. 특히, Geoff Hintin lab에서 연구한 acoustic modeling과 speech recognition관한 내용에서 neural network는 음성인식에 매우 좋은 성능을 보였다. 2012년에는 Geoff Hinton lab의 Alex Krizhevsky가 영상 인식에 관한 landmark paper(중요한 논문)를 냈다. 이 논문은 ImageNet Classification에서 최초로 CNN을 사용했고 매우 좋은 성능을 보여줬다. 이 알고리즘은 AlexNet라고도 불리는데, *ImageNet benchmark의 error를 극적으로 감소시켰다 (기존 인식 오류를 16%까지 줄인 획기적인 성능의 알고리즘, 현재 120만개의 이미지를 1000종으로 분류하는 ImageNet의 알고리듬의 바탕이 되지 않았을까?). AlexNet은 CNN의 현대화 바람을 이르켰다. 1988년 Yann LeCun이 최초로 CNN을 학습시키기 위해 backprob과 gradient-based learning을 적용했고, 실제로 이 방법은 문서 인식에서 잘 동작해 우편 서비스에서 우편번호 인식에 널리 쓰였다. AlexNet은 Yann LeCun의 CNN과 크게 달라보이지 않지만 더 크고 깊어졌다. 또한, ImageNet dataset이나 웹 이미지와 같은 대규모 데이터를 활용할 수 있었고, GPU의 힘도 이점으로 작용했다.
ConvNets는 오늘날 모든 곳에 쓰인다. AlexNet의 ImageNet 데이터 분류 결과를 살펴보자면 이미지 검색에 정말 좋은 성능을 보여주고, 객체 인식에서도 ConvNets를 사용한다 (영상 내 객체가 어디에 있는지 잘 찾아냄). 얼굴인식의 예를 보면 얼굴 이미지를 입력으로 받아서 이 사람이 누구인지에 대한 확률을 추정할 수 있고, 비디오에도 활용해 단일 이미지의 정보 뿐만 아니라 시간적 정보도 같이 활용할 수 있다. 또한, pose recognition도 가능해 어깨나 팔꿈치와 같은 다양한 관절들을 인식할 수도 있다. Convnet을 가지고 게임도 할 수 있는데, 더 깊은 강화학습을 통해 Atari 게임을 하거나 바둑을 두는 모습이 이 예시다. 이렇게 현재, ConvNets은 이 모든 일들에서 아주 중요한 역할을 하고 있다 (은하 분류, 표지판 인식, 고래 분류, 항공지도를 통함 건물/길 분류 등). 이미지 분류나 인식을 넘어서 Image Captioning에도 쓰인다 (이미지가 주어지면 이미지에 대한 설명을 문장으로 만들어 내는 것). Neural Network를 이용해 예술작품도 만들어 낼 수 있다. Style Transfer라고 원본 이미지를 가지고 특정 화풍으로 다시 그려주는 알고리즘도 존재한다.
*ImageNet 스탠포드대학의 컴퓨터비전랩, 페이페이리 교수의 주도로 2010년에 만들어진 대회로 트레이닝셋을 주고 이미지 분류 문제를 얼마나 잘 맞출 수 있는지 겨루는 대회. 대회를 통해 현재 딥러닝 신경망 알고리즘들이 급속도로 발전함.
<Convolutional Neural Network>
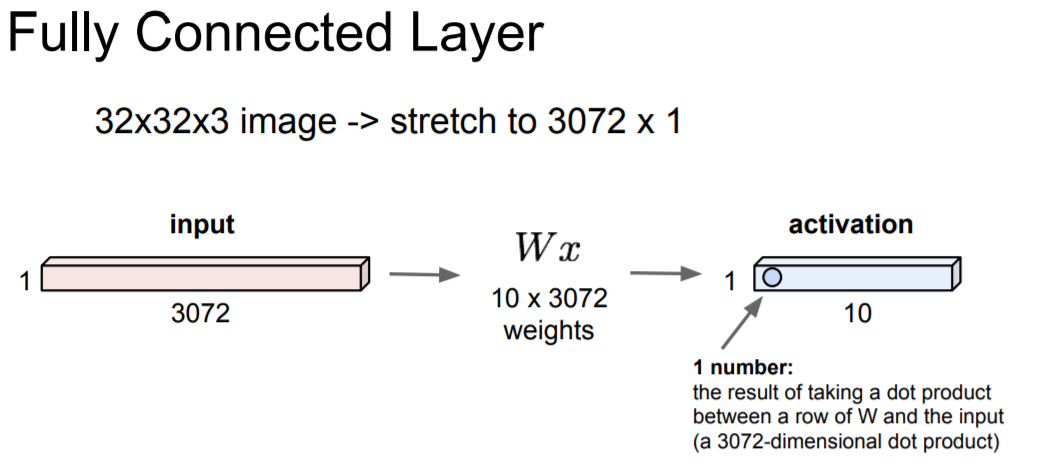
Fully Connected Layer 어떤 벡터를 가지고 연산을 하는 것이다. 밑에 예시를 보면 입력 값으로 32 x 32 x 3 의 이미지가 있고 이 이미지를 길게 펴서 3072차원의 벡터로 만든다. 그리고 가중치 W (10x3072 행렬)를 벡터와 곱하고 (Wx) activiation을 이 layer의 출력값으로 얻는다. 이 예시의 경우 10개의 출력값을 가진다.
Convolution Layer와 Fully Connected Layer의 차이점은 Convolution Layer는 기존의 구조를 보존시킨다는 것이다. 위의 예시와 같이 32x32x3의 이미지를 받아서 하나의 긴 벡터로 늘리는게 아니라 기존의 이미지 구조 그대로 유지한다. 그리고 파란색의 작은 필터(5x5x3)가 가중치가 된다. 우리는 이 필터를 가지고 이미지를 슬라이딩하면서 공간적으로 내적을 수행하게 된다.
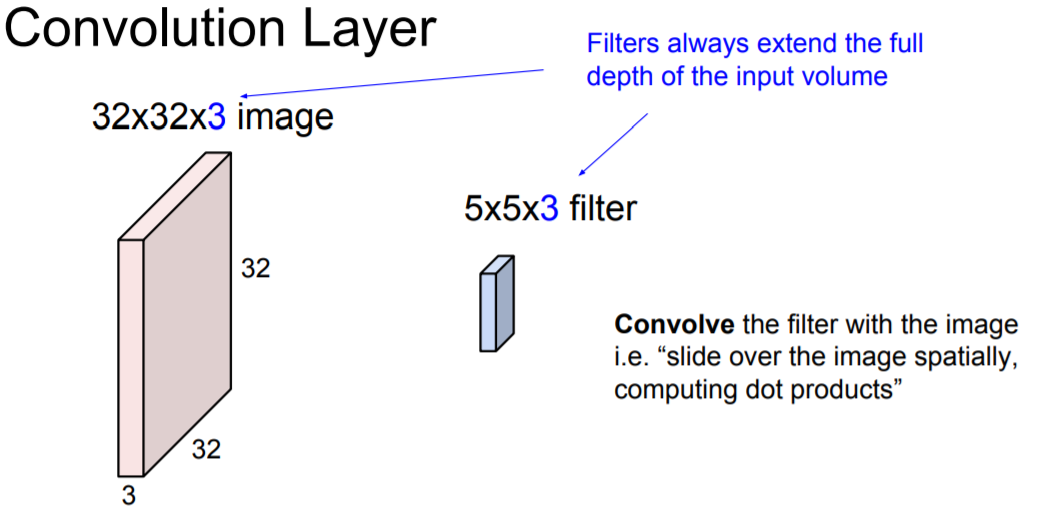
필터는 이미지의 깊이 만큼 확장된다 (이 예시에서는 3). 하지만 이미지의 아주 작은 부분만 취할 수 있다 (전체 32x32 이미지에서 5x5 만 취함). 깊이를 봤을 때 전체 깊이를 모두 취하기 때문에 5x5x3(깊이)가 된다. 우리는 이 필터를 이미지의 어떤 공간에 겹쳐놓고 필터의 각 w와, 이에 해당하는 이미지의 픽셀을 곱해준다. 기본적으로 W^tx + b를 수행하는 것이다.
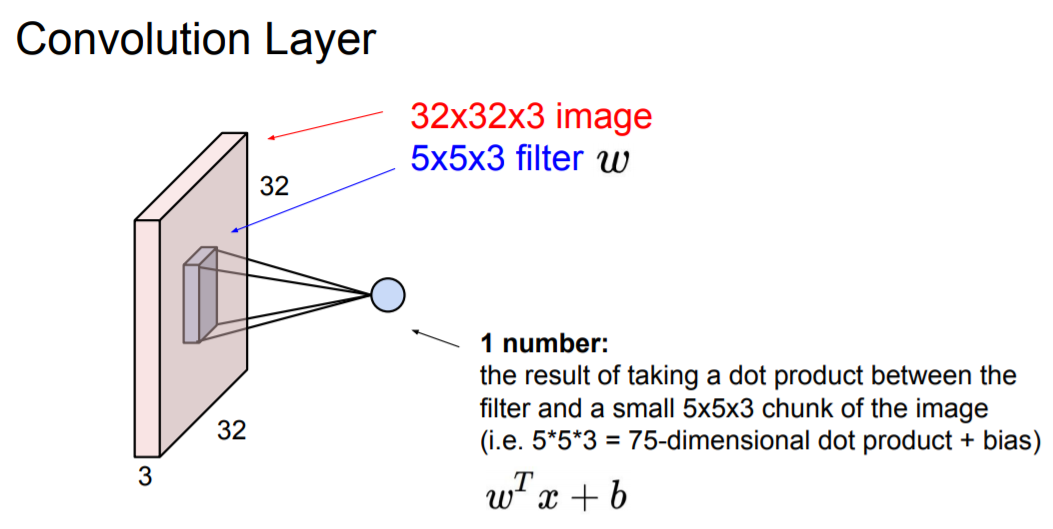
필터가 슬라이딩 할 때, Convolution은 이미지의 좌상단부터 시작한다. 필터의 모든 요소를 가지고 내적을 수행하게 되면 하나의 값을 얻게된다. 그리고 계속 슬라이딩 한다. Conv연산을 수행하는 값들을 다시 Output activation map에 해당하는 위치에 저장된다. 밑에 예시를 보면, 입력 이미지와 출력 activation map의 차원이 다르다는 것을 알 수 있다 (입력은 32 x 32 이고 출력은 28 x 28).
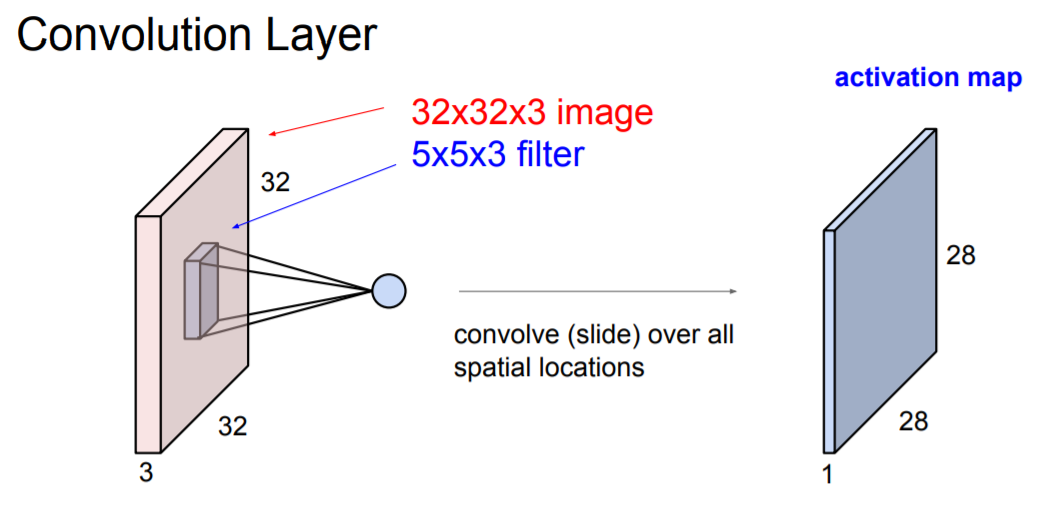
보통 Convolution Layer에서는 여러개의 필터를 사용하는데, 필터마다 다른 특징을 추출하고 싶기 때문이다. 예를 들어, 두 번째 필터인 초록색의 5 x 5 x 3 필터를 연산하고 나면, 앞서 계산했던 activate map과 같은 크기의 새로운 map이 만들어 진다. 한 Layer에서 원하는 만큼 여러개의 필터를 사용할 수 있다. 아래 그림과 같이 5x5 필터가 6개가 있다면 총 6개의 activation map을 얻게 되는 것이다.
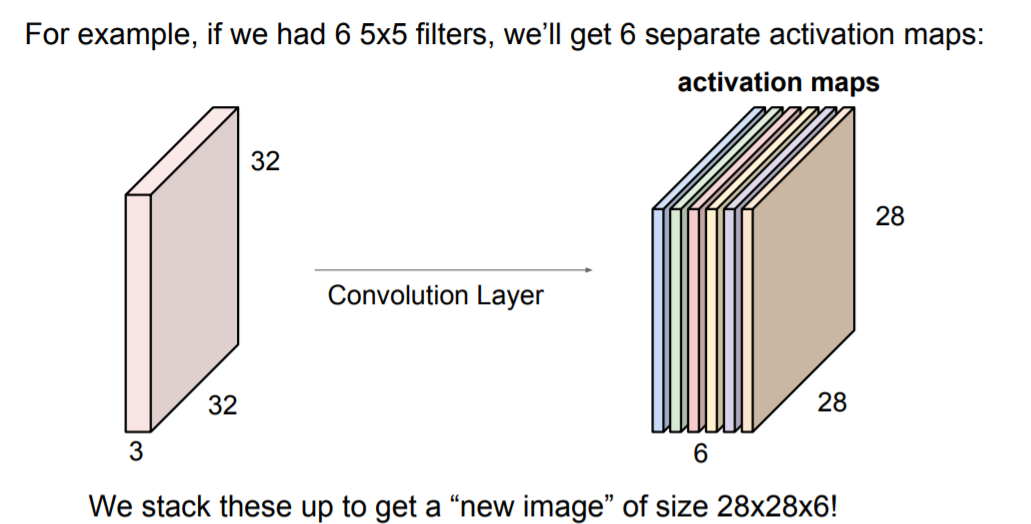
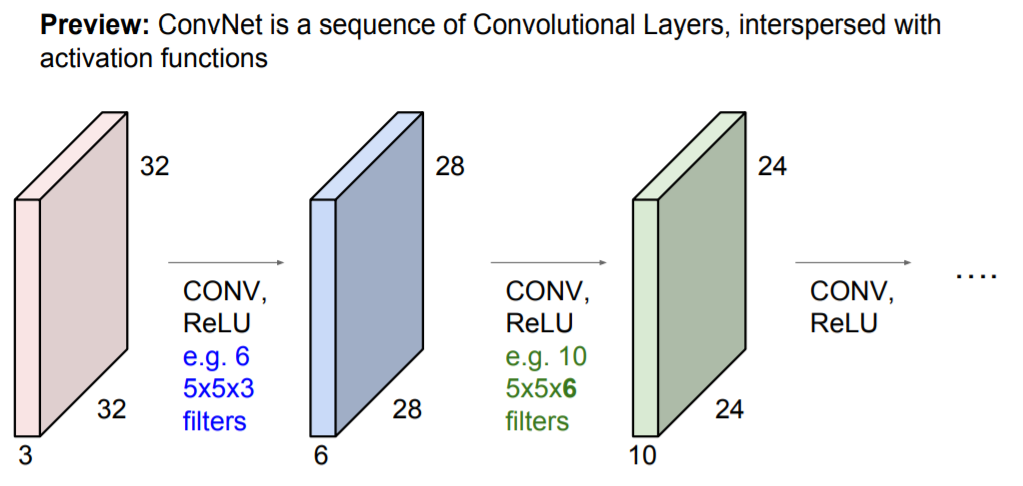
CNN은 이런식으로 Convolution Layer의 연속된 형태가 된다. 그리고 각각을 쌓아 올리게 되면 Linear Layer로 된 Neural Network가 되고 그 사이사이에 ReLU같은 activation function을 넣는다. 그럼 Conv-ReLU 가 반복되고 가끔은 pooling layer도 들어간다. 각 Layer의 출력은 다음 Layer의 입력이 되고 각 Layer는 여러개의 필터를 가지고 각 필터마다 각각의 출력 map을 만든다. 그러므로 여러개의 Layer들을 쌓고나서 보면 결국 각 필터들이 계층적으로 학습을 하는것을 볼 수 있다.
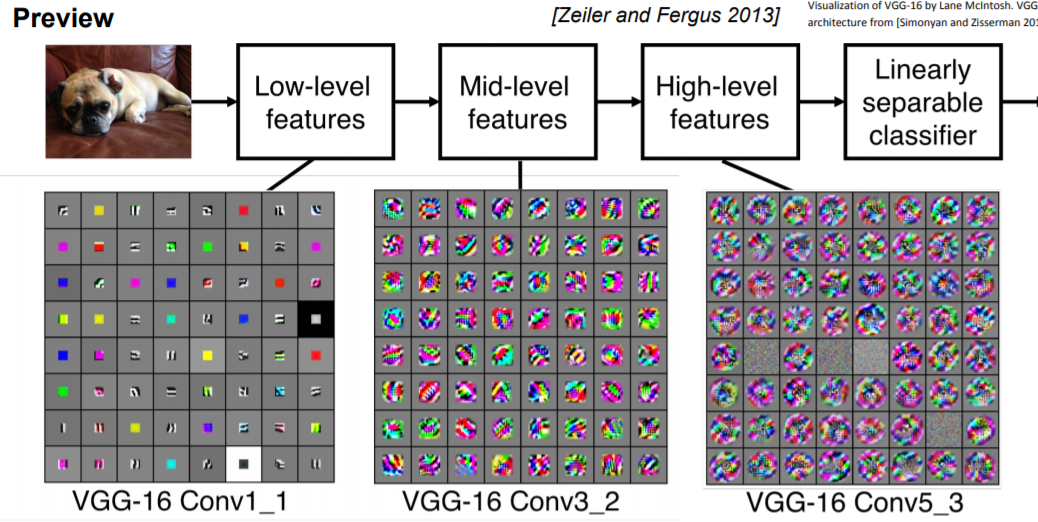
앞쪽에 있는 필터들은 low-level feature를 학습한다 (edge 끝부분&가장자리). Mid-level을 보면 좀더 복잡한 특징을 가지게 된다 (corners and blobs 모서기&작은 색깔 부분). High-level features를 보면 좀 더 객체와 닮은 것들이 출력으로 나온다.
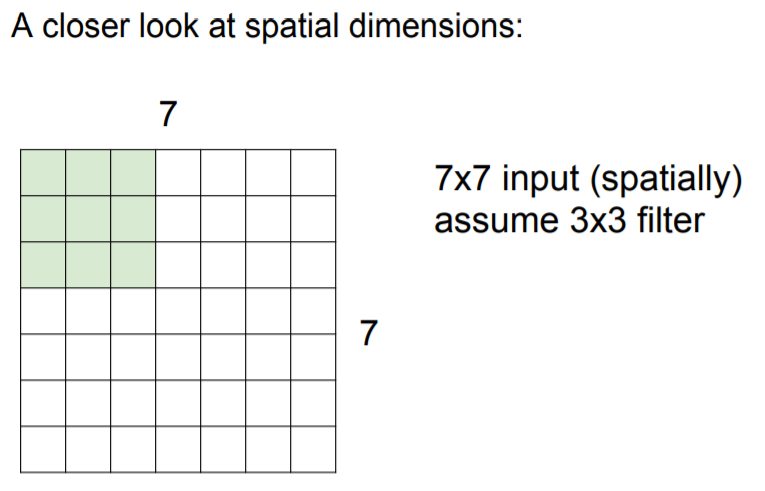
<Spatial dimension>
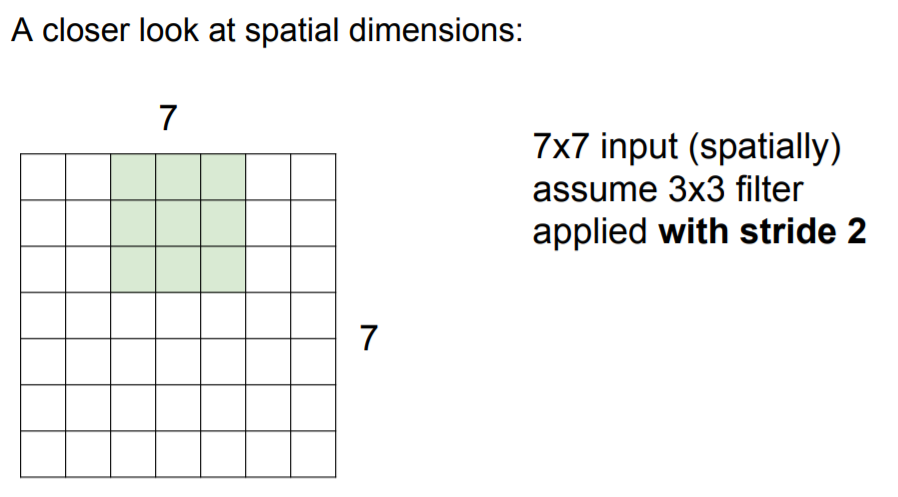
32 x 32 x 3 이미지가 있고 이 이미지를 5 x 5 x 3 필터를 가지고 연산을 수행할 때, 어떻게 28 x 28 activation map이 생기는지 알아보자. 간단한 예시로 7 x 7 입력에 3 x 3 필터가 있다고 했을 때 우리는 이 필터를 가장 왼쪽 상단에 위치시키고 해당 값들의 내적을 수행한다. 이 값들은 activation map의 좌 상단에 위치할 것이다. 그리고 다음 단계로 필를 오른쪽으로 한칸 움직인다. 그러면 또 하나의 값을 얻을 수 있고, 계속 반복하다보면 결국 5 x 5의 출력을 얻게 된다. 왜내하면 이 슬라이드 필터는 좌우 방향으로는 5번만, 상하 방향으로도 5번만 수행가능하기 때문이다. 우리는 필터 슬라이딩을 한칸씩 진행했는데, 이때 움직이는 칸을 stride라고 한다.
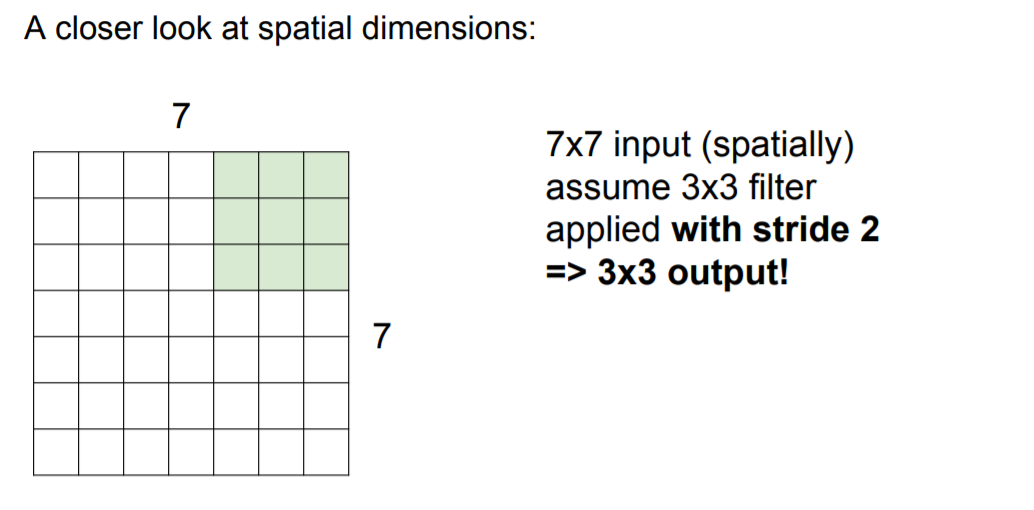
위에서는 stide = 1을 사용했다. stride = 2를 사용하면 어떨까? 다시 왼쪽 상단부터 시작해서 움직이면서 1칸은 건너뛰고 그 다음칸으로 이동해서 계산한다. 그럼 출력은 3 x 3이 된다.
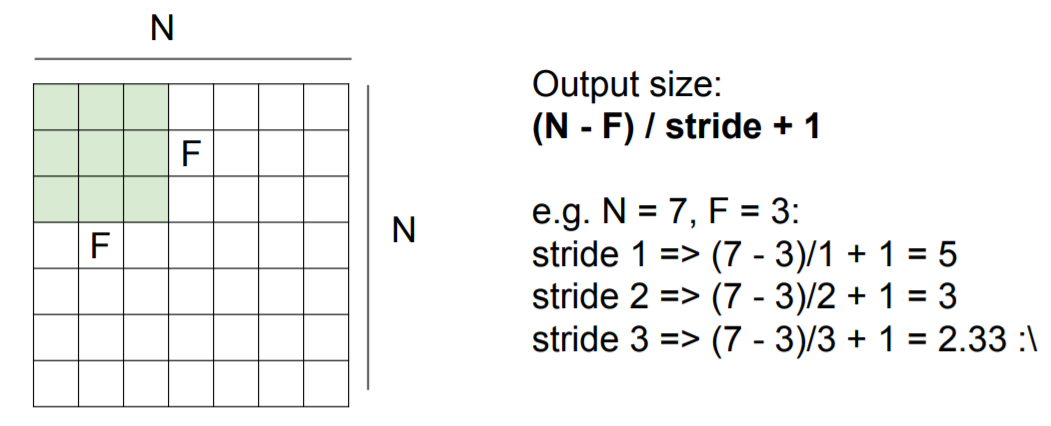
stride = 3인 경우는 이미지를 슬라이딩해도 필터가 모든 이미지를 커버할 수 없다. 이미지에 잘 맞아떨어지지 않으므로 실제로 이렇게 되면 잘 동작하지 않는다고 볼 수 있다. 이로 인해 불균형한 결과를 볼 수도 있기 때문에 이렇게 stride값을 설정하면 안된다. 이런 상황을 방지하기 위해 출력의 사이즈가 어떻게 될 것인지를 계산할 수 있는 수식을 사용할 수 있다. 입력의 차원이 N이고 필터 사이즈가 F이고 stride가 몇이다 라고 주어지게 되면 출력의 크기는 (N - F) / stride + 1 이다. 이 수식을 이용하면 어떤 필터 크기를 사용해야 하는지 알 수 있다.
Zero-padding은 가장자리의 필터 연산을 수행하도록 하고 출력의 사이즈 의도대로 만들어 준다. 이는 입력 사이즈를 유지할 수 있고 코너를 처리할 수도 있다. Zero-padding은 이미지의 가장자리에 0을 채워넣음으로써 왼쪽 상단의 자리에서도 필터 연산을 수행할 수 있게 된다. Zero-padding을 하면 새 출력이 7이 되어 출력의 차원이 입력의 차원과 같아진다. 출력은 (7 x 7 x 필터의 개수)가 된다.

Zero-padding은 필터가 닿지 않는 모서리 부분에서도 값을 뽑을 수 있게 해주는 하나의 방법이다. zero가 아닌 mirror나 extend하는 방법도 있는데, zero-padding는 제법 잘 동작하는 방법 중 하나이다. 아래 사진은 Conv layer 요약본이다. 우리는 몇개의 필터를 쓸건지, 필터 크기는 몇인지, stride는 몇으로 할지 zero-padding은 몇 으로 할지 정해줘야한다. 그리고 앞서 말한 수식을 이용해서 출력의 사이즈가 어떻게 될지 계산도 해야한다. 일반적으로는, 필터 사이즈는 3x3, 5x5, Stride는 보통 1이나 2, padding은 그 설정에 따라 조금씩 다르게, 필터의 갯수는 32, 64, 128, 512 등 2의 제곱수로 한다.

* 5 x 5 필터가 있다면 한 뉴런의 Receptive field 가 5 x 5 다라고 할 수 있다. Receptive field는 한 뉴런이 한 번에 수용할 수 있는 영역을 의미한다.
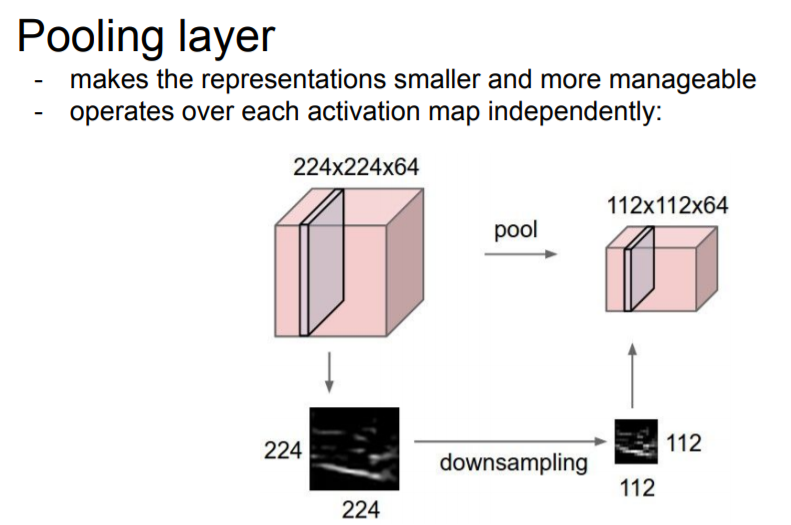
CNN에는 Conv Layer와 Pooling Layer, 그리고 다른 비선형 연산들도 있다. Pooling Layer는 Representation들을 더 작고 관리하게 쉽게 해준다. Representation을 작게 만드는 이유는 파라미터의 수가 줄게 되고, 공간적인 불변성(invaiance) 을 얻을 수도 있다. Pooling Layer가 하는 일은 아주 간단한데, downsample하는 것이다. 예를 들어, 224 x 224 x 64 인 입력이 있다면, 이를 112 x 112 x 64 로 공간적으로 줄여준다. 여기서 중요한 점은 depth (깊이)에는 영향을 주지 않는다.
Max Pooling이 일반적으로 쓰이는데, Pooling에도 필터 크기를 정할 수 있다 (얼마만큼의 영역을 한 번에 묶을지를 정하는 것). 2 x 2 필터가 있고 stride가 2일 때 Conv Layer가 했던 것 처럼 슬라이딩하면서 연산을 수행하지만, 내적을 하는 것이 아니라 필터 안에 가장 큰 값 중에 하나를 고른다. 밑에 사진을 보면 빨간색 영역에서는 6이 제일 크고 초록색 영역에서는 8이 제일 크다. 나머지도 마찬가지로 3과 4의 값이 나온다. Pooling 할 때는 보통은 겹치지 않는 것이 일반적이다. 기본적으로 downsample을 하고싶은 것이기 때문에 한 지역을 선택하고 값 하나 뽑고, 또 다른 지역 선택하고 값 하나 뽑는식으로 진행된다. Max pooling 대신에 Average Pooling도 사용할 수 있지만, Max pooling은 그 지역이 어디든, 어떤 신호에 대해 얼마나 그 필터가 활성화 되었는지를 알려주기 때문에 사용한다. (?) 요즘에는 사람들이 downsample할때 pooling을 하기보단 stride를 많이 사용하고 있는 추세이다. Pooling 도 일종의 stride 기법이라고 볼 수 있다고 본다.
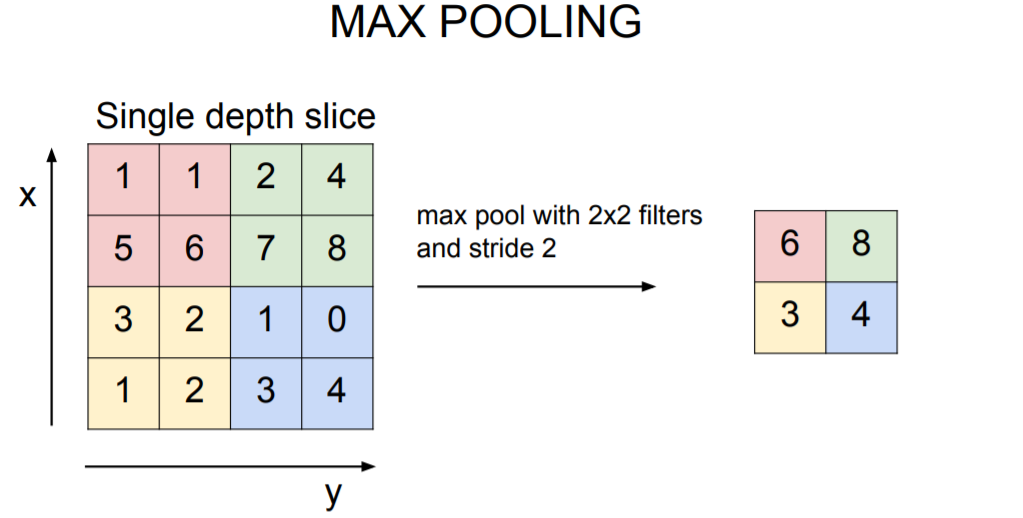
Pooling Layer에는 몇가지 디자인 초이스가 있는데, 입력이 W(width), H(Height), D(Depth) 이면 이를 통해 Filter Size를 정해줄 수 있다. 여기에 Stride까지 정해주면, 앞서 Conv Layer에서 사용했던 수식을 그대로 이용해 출력값을 계산할 수 있다 ((W - Filter Size) / Stride + 1). 사람들은 보통 pooling layer에서는 zero-padding를 사용하지 않는다. Pooling 할때는 padding을 고려하지 않고 그냥 downsample만 하면 된다. 가장 널리 쓰이는 필터사이즈는 2 x 2, 3 x 3 이고 보통 stride는 2로 한다.

FC Layer는 마지막에 존재한다. 마지막 Conv Layer의 출력은 3차원 volume으로 이루어진다. 이 값들을 전부 펴서(stretch) 1차원 벡터로 만들고 FC Layer의 입력으로 사용한다. 그렇게 되면 Conv Net의 모든 출력을 서로 연결하는 것이다. 마지막 Layer부터는 공간적 구조(spatial structure)를 신경쓰지 않아도 된다. 전부 다 하나로 통합시키고 최종적인 추론을 하면 Score가 출력된다.

'AI > CS231n' 카테고리의 다른 글
| [8강] Deep Learning Software (0) | 2020.11.28 |
|---|---|
| [6강] Training Neural Networks I (0) | 2020.11.14 |
| [4강] Introduction to Neural Networks (0) | 2020.10.31 |
| [3강] Loss Functions and Optimization (0) | 2020.10.30 |
| [2강] Image Classification (0) | 2020.10.17 |