[8강] Deep Learning Software
오늘 강의에서는 딥러닝 소프트웨어에 대해 이야기할 예정이다. 매년 많이 바뀌는 주제라 흥미로운 주제 중에 하나라고 한다. 지난 시간에는 SGD, Momentum, Nesterov, RMSProp, Adam 등 딥러닝 최적화 알고리즘에 대해 살펴보았다. 이 방법들을 모두 기본적인 SGD를 조금씩 변형시킨 방법이었는데, 구현이 간단한데, 네트워크의 수렴속도가 빨랐다. 그리고 regularization (일반화) 중에 특히 Dropout에 대해 배웠다. Dropout은 forward pass에서 네트워크의 임의의 부분을 0으로 설정하고, test time에서는 그 noise를 marginalize out 했었다. 또한 transfer learning (전이 학습)에 대해서도 배웠다. 어떠한 데이터셋에 대해 pre-trained 된 큰 네트워크인 (만들어진) model을 다운받아서 우리의 데이터셋에 맞춰 fine-tune 하는 방법이었다. 전이학습을 이용하면 데이터셋이 많지 않더라도 다양한 딥러닝 문제를 다룰 수 있다. 이번 시간에는 화제를 좀 돌려서 소프트웨어와 하드웨어가 동작하는 방식에 대해서 살펴보고, 특히 우리가 실제로 모델을 학습시킬 때 사용하는 소프트웨어들을 조금 자세하게 다뤄볼 것이다.
- CPU / GPU 에 대해 배우고,
- 강의가 진행됐던 2017년 기준 사람들이 많이 사용했던 딥러닝 프레임워크에 대해 이야기 할 예정이다.
1. CPU vs GPU
CPU와 GPU에 대해 알아보자. 컴퓨터에는 CPU와 GPU가 존재하고 딥러닝은 GPU를 사용하는데, 우리는 왜 딥러닝에서 GPU가 CPU보다 더 좋은지에 대해서 명확하게 언급한 적이 없었고 이번 강의에서 그 부분을 짚고 넘어갈 예정이다. GPU는 왜 딥러닝에서 중요할까? GPU는 graphics card 혹은 Graphics Processing Unit으로 보통 게임을 위해 만들어진 하드웨어로 computer graphic를 랜더링 하기 위해 만들어졌다. GPU의 양대산맥으로 NVIDIA와 AMD가 있는데 딥러닝 분야에서는 NVIDIA 독점적이라고 볼 수 있는데 2017년 기준으로 NVIDIA가 수년간 딥러닝에 많은 공을 기울여 엔지니어들이 딥러닝에 적합한 하드웨어를 만들기 위해 많은 노력을 했다고 한다. 2020년 2월 기준으로도 역시 NVIDIA(앤비디아) 딥러닝 분야를 독점하고 있는 것 같다.
lambdalabs.com/blog/choosing-a-gpu-for-deep-learning/
Core의 수와 명령어를 처리하는 방식의 차이
CPU와 GPU의 차이는 무엇일까? GPU와 CPU모두 임의의 명령어를 수행할 수 있는데, CPU의 경우 core의 수가 적고 (보통 4-6개, 많으면 10개), 고성능의 상업 GPU의 경우 수천개의 코어가 있다. 코어 수만 보면 CPU보다 GPU의 코어수가 훨씬 많지만 CPU는 독립적으로 많은 일을 수행할 수 있다. Hyperthreading 기술로 CPU는 8 ~ 20개의 스레드를 동시에 실행시킬 수 있다고 한다. 코어는 CPU의 머리(물리적인 의미가 높은), 쓰레드는 사고방식(추상적인 의미가 높은)
라고 간단히 생각할 수 있는데 하나의 코어에서 여러(두 가지)일을 하는 것이 멀티스레드라고 하며 인텔에서는 하이퍼스레딩이라고 표현한다고 한다. 코어 수와, 하이퍼스레딩 유무에 따라 CPU의 성능차이가 존재한다. CPU는 많은 일을 빨리 할 수 있다. 하지만 GPU는 코어들은 CPU와 비교했을 때, 많은 일을 할 수 없고, 독립적으로 동작하지 않으며, 많은 코어들이 하나의 테스크를 병렬적으로 수행하는 형태이다. GPU는 하나의 일을 병렬적으로(Parallel) 나누어 작업하기 때문에 하나의 일을 처리하는데에 CPU에 비해 속도가 빠르다고 볼 수 있다.
메모리 사용 방식의 차이
CPU는 대부분의 메모리를 RAM에서 끌어다 쓰는 반면 GPU는 RAM이 내장되어 있고, 코어 사이에 캐싱을 위한 다계층 캐싱 시스템을 가지고 있다. CPU는 메모리를 RAM으로부터 끌어다 쓰고 GPU는 내장메모리를 사용한다.
Matrix Multiplication
CPU는 다양한 일을 할 수 있기 때문에 범용처리에 적합하고, GPU는 병렬처리에 특화되어있다. 그래서 GPU에서 잘 동작할 수 있는 적합한 알고리즘이 바로 행렬곱(Matrix multiplicaiton) 연산이다. 오른쪽 행렬은 왼쪽 두 행렬의 내적이고 내적 연산은 모두 서로 독립적이라고 볼 수 있는데, 오른쪽의 결과행렬을 살펴보면 알 수 있듯이, 각각의 원소가 전부 독립적이기 때문에 모두 병렬로 수행될 수 있으며 이때 각 원소들은 모두 같은 일을 수행한다 (두개의 벡터를 내적하는 것, 입력 데이터만 다름). GPU는 결과 행렬의 각 요소들을 병렬로 계산할 수 있기 때문에 이런 연산들은 엄청 빠르게 할 수 있다. 실제로 아주 큰 병렬화 문제에 대해서는 GPU의 처리량이 압도적이다. Convolution를 예로 들면 convolution에는 입력(텐서)과 가중치가 있고, Cov 출력은 입력과 가중치간의 내적이라고 볼 수 있는데 GPU를 사용하면 이 연산을 각 코어에 분배시켜서 CPU에 비해 아주 빠르게 연산할 수 있다.
- 행렬 곱셈의 결과 행렬은 앞 행렬의 행벡터와 뒤 행렬의 열벡터를 dot product라는 내적의 한 종류를 적용한 값을 가지는 행렬이라고 할 수가 있다.
- 내적이란 벡터의 곱셈 연산 중 하나로, 벡터를 곱하는 방법은 2가지가 있는데, 하나는 외적(벡터곱, cross product)이고 다른 하나는 내적(스칼라곱,점곱,inner product). 두 벡터를 내적했을 때의 결과는 상수지만 외적했을 때의 결과는 벡터.
- A tensor is a vector or matrix of n-dimensions that represents all types of data.

Programming GPUs
GPU에서 직접 실행되는 코드를 작성할 수 있는 방법이 있는데, NVIDIA에서 지원하는 CUDA를 사용하면 된다. C언어랑 비슷하게 생겼는데 GPU에서만 실행되는 코드이다. 하지만 CUDA코드를 작성하는 것은 세심하게 메모리 구조를 관리하고 고려해야되는 등 상당히 까다로워 우리가 직접 효율적인 CUDA코드를 작성하는 것은 어렵다고 볼 수 있다. 그래서 NVIDIA는 GPU에 최적화된 기본 연산 라이브러리를 배포해왔는데, 예를들어 cuBLAS는 다양한 행렬곱을 비롯한 연산들을 제공해준다. cuDNN이라는 라이브러리도 있는데, convolution, forward/backward pass, batch norm, rnn 등 딥러닝에 필요한 거의 모든 기본적인 연산들을 제공해준다. NVIDIA가 이렇게 자사의 GPU에 효율적으로 동작하는 라이브러리를 배포해주기 때문에 우리가 실제로 딥러닝에 사용하기 위해 CUDA 코드를 직접 작성하는 일은 없을 것이다. CUDA 말고도 OpenCL이라는 조금 더 범용적인 언어가 있는데, OpenCL은 NVIDIA GPU에서만 동작하는 것이 아니라 AMD와 CPU에서도 동작한다. 하지만 OpenCL은 2017년 기준 딥러닝에 최적화된 연산이나 라이브러리가 개발되지않아서 CUDA보다는 성능이 떨어진다.

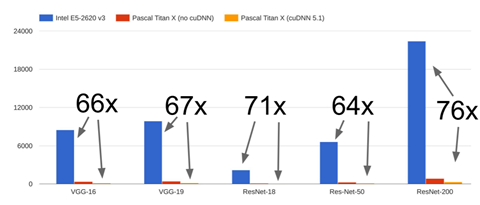
Benchmark 성능 비교 평가
- CPU와 GPU의 성능 벤치마크 비교
GPU의 경우는 Pascal TitanX, CPU의 경우 Intel E5 Processor로 벤치마크
GPU가 보통 65 - 75배 빠름
(CPU에서는 성능을 최대화 시킬 수 있을만큼 공을 들이기 않았기 때문에 CPU에게 조금 불리한 벤치마크)
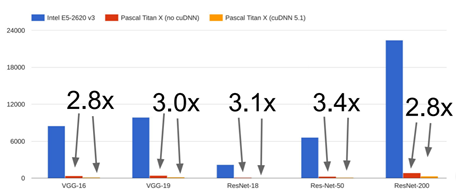
- CUDA와 cuDNN의 성능 벤치마크 비교 (Convolution 연산에 cuDNN을 사용한 것과 일반적인 CUDA 사용한 것)
Bottleneck 병목현상
한 번에 처리할 수 있는 데이터의 양보다 처리할 수 있는 능력이 충분하지 않을 경우 발생하는 문제
실제로 GPU로 학습을 할 때 생기는 문제 중 하나는 바로 Model과 Model의 가중치는 전부 GPU RAM에 상주하고 있는 반면에 실제 Train data(Big data)는 SSD와 같은 하드드라이브에 있는 경우이다. 그래서 train time에 디스크에서 데이터를 읽어드리는 작업을 세심하게 신경쓰지 않으면 보틀넥이 발생할 수 있다. GPU는 forward/backward 가 아주 빠른 것은 사실이지만, 디스크에서 데이터를 읽어드리는 것이 보틀넥이 된다. 해결책 중 하나는 바로 데이터셋이 작은 경우나 서버에 RAM 용량이 크다면 데이터 전체를 RAM에 올려 놓거나 데이터를 읽는 속도를 개선시키는 것이다. 또 다른 방법은 CPU의 다중스레드를 이용해서 데이터를 RAM에 미리 올려 놓는 방법(pre-fetching) 이다.
Deep Learning Framwork
오늘날에는 다양한 Deep Learning Framework들이 사용되고 있는데, 이번 강의에서는 주로 TensorFlow와 Pytorch를 다룬다고 합니다. 한가지 짚고 넘어갈 부분은, 딥러닝 프레임워크의 초창기 세대는 학계에서 구축되었었는데(Caffe는 Berkeley에서, Torch는 NYU에서 개발된 후 Facebook과 공동연구 시작), 다음세대의 딥러닝 프레임워크들은
기업(industry)에서 나왔다 (Caffe2와 PyTorch는 Facebook에서, TensorFlow는 Google). Academia에서 industry로의 이동해 기업들이 강력한 프레임워크를 제공하고 있다.
Deep Learning Framework를 이용하면 우리가 굳이 코드를 손으로 작성하지 않고도 Deep Learning Model들을 구현할 수 있다.
'AI > CS231n' 카테고리의 다른 글
| [11강] Detection and Segmentation (0) | 2020.12.19 |
|---|---|
| [9강] CNN Architectures (0) | 2020.12.05 |
| [6강] Training Neural Networks I (0) | 2020.11.14 |
| [5강] Convolutional Neural Networks (0) | 2020.11.07 |
| [4강] Introduction to Neural Networks (0) | 2020.10.31 |