[11강] Detection and Segmentation
지난 시간에는 Recurrent Neural Networks를 소개했었다. 오늘은 Detection과 Segmentation등 Compuver Vision task들을 소개할 예정이다. Segmentation, Localization, Detection 등 다양한 Computer Vision Tasks와 이 문제들을 CNN으로 어떻게 접근해 볼 수 있을지 고민할 예정이다.
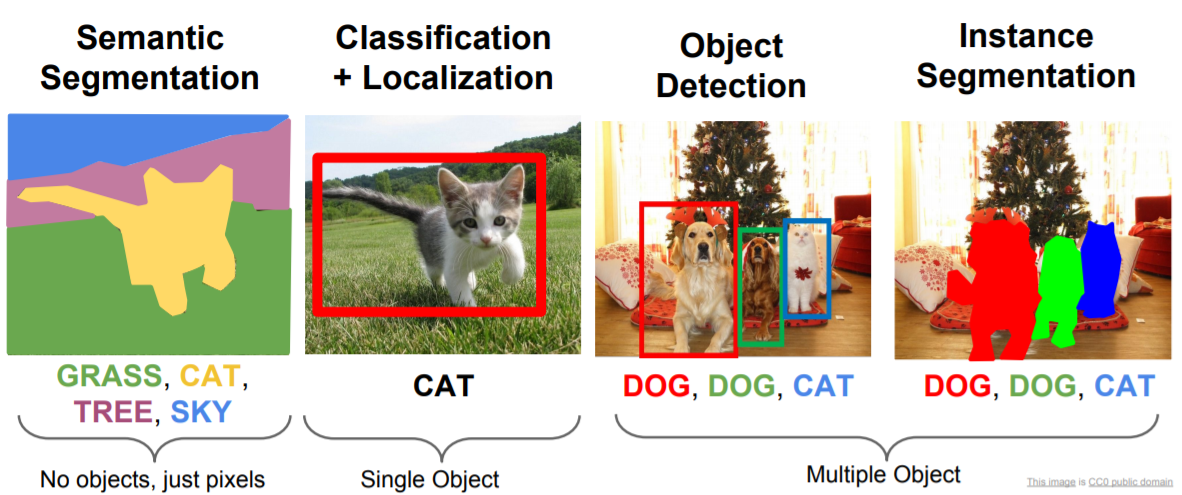
Sementic Segmentation
Sementic Segmentation 문제에서는 입력은 이미지이고 출력으로 이미지의 모든 픽셀에 카테고리를 정한다. 밑에 왼쪽 예제를 보면 입력은 고양이이고, 출력은 모든 픽셀에 대해서 그 픽셀이 "고양이, 잔디, 하늘, 나무, 배경"인지를 결정하는 것이다. Sementic Segmentation 에서도 Classification에서 처럼 카테고리가 있다. 하지만 다른 점은 Classification 처럼 이미지 전체에 카테고리 하나가 아니라 모든 픽셀에 카테고리가 매겨지는 형태다. 또 하나 유의해야 할 점은, semantic segmentation은 개별 객체를 구분하지 않는다. 오른쪽 이미지를 보면 소 두마리가 있는데, Semantic Segmentation의 경우에는 픽셀의 카테고리만 구분하기 때문에 소 두마리를 구별할 수 없고 "cow"라고 레이블링된 픽셀 덩어리만 얻을 수 있다. 이는 Sementatic Segmentation의 단점이라고도 할 수 있고, 나중에 배울 Instance Segmentation이 문제를 해결할 수 있다.

Semantic Segmentation 문제에 접근해볼 수 있는 방법 중 하나는 Classification을 통한 접근이다. Semantic Segmentation을 위해서 Sliding Window를 적용하는 방법이 있는데, 입력 이미지를 아주 작은 단위로 쪼갠다. 밑에 예제를 보면 소의 머리 주변에서 영역 3개를 추출했다. 그 다음에 우리는 이 작은 영역만을 가지고 Classification 문제를 푼다고 생각해 보는 것이다. 즉, 해당 영역이 어떤 카테고리에 속하는지를 정하는 것이다. 이는 이미지 한장을 분류하기 위해서 만든 모델을 이용해서 이미지의 작은 영역을 분류하게 하게 해볼 수 있을 것같다. 이 방법이 어느정도 동작할 수도 있지만, 그렇게 좋은 방법이 아니다. 왜냐하면 모든 픽셀에 대해서 작은 영역으로 쪼개고, 이 모든 영역을 forward/backward pass 하는 일은 상당히 비효율적으로 비용이 엄청나게 크기 때문이다. 또한, 서로 다른 영역이라도 인접해 있으면 어느정도는 겹쳐있기 때문에 특징들을 공유할 수도 있다. 그래서 이렇게 개별적으로 접근하는 방법은 나쁜 방법이라고 생각할 수 있다. 하지만, Semantic Segmentation을 하고자 할 때 가장 먼저 생각해 볼 수 있는 방법일 것이다.

또 다른 방법 (개선된 방법)으로는 Fully Convolutional Network가 있다. 이는 이미지 영역을 나누고 독집적으로 분류하는 방법은 아니다. FC-Layer가 없고 Convolution Layer 구성된 네트워크이다. Conv Layer들을 쌓아올면 이미지의 공간정보를 손실하지 않고 학습 할 수 있다. 이 네트워크의 출력 Tensor는 C x H x W로, C는 카테고리의 수이다. 그리고 이 출력 Tensor는 입력 이미지의 모든 픽셀 값에 대해 Classification Scores를 매긴 값이다. 이 네트워크를 학습시키려면 우선 모든 픽셀의 Classification loss를 계산하고 평균 값을 취한 다음 기존처럼 back propagation을 수행하면 된다.

Training data는 어떻게 만들까? 입력 이미지에 모든 픽셀에 대해서 레이블링을 하는 작업을 거쳐야한다. 객체의 외관선만 그려주면 안을 채워넣는 식으로 툴을 만들어서 사용하는 경우도 있는데, 일반적으로는 Train data를 만들거나 수집하는것은 비용이 상당이 클 것이다. 손실 함수는 어떻게 결정될까? fully convolutional network 문제에서는 모든 픽셀을 Classification하고 출력의 모든 픽셀에 Cross entropy를 적용하는 것이다. 그리고 이 모델을 학습시킬 때, 모든 픽셀의 카테고리를 알고 있다는 가정이 있어야된다 image classification이랑 비슷한 경우라고 생각하면 된다. Semantic Segmentation에서도 클래스의 수가 고정된다고 생각하면 된다.
어떤식으로 동작할까? Max pooling, Stride Convolution 등으로 특징맵을 Downsample한다. Image Classification 에서는 이렇게 downsampling 한 다음에 FC-Layer가 있었다. 하지만 여기에서는 Spatial Resolution을 다시 키운다. 출력이 다시 입력 이미지의 해상도와 같아지도록 하는 것이다 (upsampling).
우리는 Convolutional Networks에서의 Downsampling에 대해서는 이미 본 적이 있다. 이미지의 Spatial Size를 줄이기 위한 Stried Conv 라던가 다양한 Pooling layer에 대해 다뤄본 적이 있다. 하지만 upsampling은 처음 접하는 개념일 것이다. Upsampling 전량 중 하나는 unpooling이다. Downsample에서의 pooling에는 average/max pooling 등이 있었다. upsampling 방법 중에는 nearest neighbor unpooling이 있다. 밑에 예제의 왼쪽을 보면 nearest neighbor unpooling 예제가 있다. 입력은 2x2 그리드이고 출력은 4x4 그리드이다. 2x2 stride nearest neighbor unpooling은 해당하는 receptive field로 값을 그냥 복사한다. 오른쪽에서 보면 bed of nails unpooling이란 방법도 있다. bed of nails upsampling이라고도 하는데, 이 방법은 unpooling region에만 값을 복사하고 다른 곳에는 모두 0을 채워넣는 방법이다. 이 경우 하나의 요소를 제외하고 모두 0으로 만든다. 이 방법이 bed of nails라고 불리는 이유는 zero region은 평평하고 non-zero region은 바늘처럼 뾰족하게 값이 튀기 때문이다.

Upsampling 하는 방법중에는 Max unpooling이란 방법도 있다. 각 unpooling과 pooling을 연관짓는 방법이다. Upsampling의 bed of nails upsampling 과 유사한데, downsampling시에 Max pooling에 사용했던 요소들을 잘 기억하고 있다가 bed of nails upsampling처럼 같은 자리에 값을 넣어주는 것이 아니라 이전 Maxpooling에서 선택된 위치에 맞게 넣어주고, 다른 곳에는 모두 0을 채워넣어 준다. 정리하자면, Low Resolution 특징 맵을 High Resolution 특징 맵으로 만들어 주는 것인데, 이 때 Low Resolution 의 값들을 Maxpooling에서 선택된 위치로 넣어주는 것이다. Semantic segmentation 에서는 모든 픽셀들의 클래스를 모두 잘 분류해야 한다. 이 때, 예측한 Segmentation 결과에서 객체들간의 디테일한 경계가 명확할수록 좋다. 하지만 Maxpooling을 하게되면 특징맵의 비균진성이 발생합니다. 즉 공간정보를 잃게 된다. Maxpooling 후의 특징 맵만 봐서는 이 값들이 Receptive field 중 어디에서 왔는지 알 수가 없다. 그래서 Unpool 시에 기존 Maxpool 에서 뽑아온 자리로 값을 넣어주면 공간 정보를 조금은 더 디테일하게 다룰 수 있다. 결국, Max pooling 에서 읽어버린 공간정보를 조금은 더 잘 유지하도록 도와주는 것이다.

4번째 upsampling 방법은 Transpose Convolution 이다. 지금까지 살펴봤던 Unpooling 방법은 정리해보면, Bed of nails, Nearest Neighbor, Max unpooling 까지 다뤘다. 이 방법들은 "고정된 함수" 이고 별도로 학습을 시키지는 않는다. Strided convolution을 다시 생각해보면 어떤 식으로 Downsampling을 해야할지를 네트워크가 학습할 수 있었다 (convolution layer with stride). Upsampling에서 이와 유사한 방법이 바로 Transpose convolution이다. Transpose convolution은 특징 맵을 Upsampling 할 때 어떤 방식으로 할 지를 학습할 수 있다. 이는 특수한 방식의 Convolution의 일종이다. 일반적인 3 x 3 (stride = 1, padding = 1) Convolution Filter가 동작하는 방식을 다시한번 살펴보자. 아래 예제를 보면, 입력은 4x4 이고, 출력도 4x4이다. 3x3 필터가 있고 이미지와 내적을 수행한다. 시작은 우선 이미지의 좌 상단 구석부터 시작한다. 내적의 결과는 출력(4x4)의 좌 상단 코너의 값이 되는 형식이다.

Strided convolution을 살펴보자. 다른점은 입력이 4x4 이고 출력은 2x2이다. 계산 방식은 기존과 유사합니다. 3x3 필터가 있고 이미지의 좌상단 구석에서부터 내적을 계산한다. 하지만 Strided convolution은 한 픽셀씩 이동하면서 계산하지 않는다. 출력에서 한 픽셀 씩 움직이려면 입력에서는 두 픽셀 씩 움직이는 방식이다. "Stride = 2" 는 입력/출력에서 움직이는 거리 사이의 비율이라고 해석할 수도 있다. 즉, 따라서 Stride = 2인 Strided convolution은 "학습 가능한 방법" 으로 2배 downsampling 하는 것을 의미한다.

Transpose convolution은 반대의 경우로, 입력이 2x2 이고 출력이 4x4 이다. Transpose convolution을 위한 연산은
조금 다르게 생겼는데, 여기에서는 내적을 수행하지 않는다. 우선 입력 특징맵에서 값을 하나 선택한다 (빨간색). 밑에 예제에서 보듯이 좌상단에서 뽑은 이 하나의 값은 스칼라 값일 것이다. 그 다음, 이 스칼라 값을 필터(3 * 3)와 곱한다. 그리고 출력의 3x3 영역에 그 값을 넣는다. Transpose convolution에서는 필터와 입력의 내적을 계산하는 것이 아니라, 입력 값이 필터에 곱해지는 가중치의 역할을 해 출력 값은 필터 * 입력(가중치) 이다. 그리고 Upsampling 시에는 입력에서 한 칸씩 움직이는 동안 출력에서는 두 칸찍 움직인다. 아래 예제에서 오른쪽 이미지 처럼 출력에서 Transpose convolution 간에 Receptive Field가 겹치는 현상이 발생할 수 있다. 이렇게 겹치는 경우에는 간단하게 두 값을 더해주면 된다. 이 과정을 반복해서 끝마치면 학습 가능한 upsampling을 수행한 것이다. Spatial size를 키워주기 위해서 학습된 필터 가중치를 이용한 것이다. 이 방법은 문헌에 따라서 부르는 이름이 다양하다. Deconvolution라는 이름이 붙기도 하는데 신호처리의 관점에서 deconvolution은 Convolution 연산의 역 연산을 의미하지만 실제로 transpose convolution은 그런 연산은 아님으로 그 이름으로 부르는 것은 그닥 좋지 않다고 한다. 딥러닝 관련 논문에서 deconvolution이라는 용어는 주의해서 이해해야한다. 그리고 간혹 upconvolution이라고 부르기도 하고, fractionally strided convolution 이라고도 한다. fractionally strided convolution이라고 이름이 붙은 이유는 stride를 input/output간의 크기의 비율로 생각하면 밑에 예제는 input : output = 1 : 2 이기 때문에 stride 1/2 convolution 이라고 할 수 있다. Backwards strided convolution이라고도 부른다. 왜냐하면 transpose conv의 forward pass를 수학적으로 계산해보면 일반 Convolution의 backward pass와 수식이 동일하기 때문이다.

classification + localization
이미지가 어떤 카테고리에 속하는지 뿐만 아니라 실제 객체가 어디에 있는지를 알고 싶을 수도 있다. 이미지를 "Cat"에 분류하는 것 뿐만 아니라 이미지 내에 Cat이 어디에 있는지 네모박스를 그리는 것이다. classification plus localization 문제는 object detection 문제와는 구별된다. localization 문제에서는 이미지 내에서 내가 관심있는 객체가 오직 하나 뿐이라고 가정한다. 더 많은 객체를 찾고 싶을수도 있겠지만, 기본적으로 이미지 내에 객체 하나만 찾아서 레이블을 매기고 위치를 찾아낸다. 이 Task를 바로 classification plus localization라고 한다. 이 문제를 풀 때도 기존의 image classification에서 사용하던 기법들을 사용할 수 있다.

아키텍쳐의 기본 구조는 다음과 같다. 네트워크는 이미지를 입력으로 받는다. 밑에 예제에서는 AlexNet를 사용했다. 마지막에 FC-Layer는 "Class score"로 연결되서 카테고리를 결정한다. FC-Layer가 하나 더 있는데, 이는 4개의 원소를 가진 vector와 연결되어있다. 이 4개의 출력 값은 width/height/x/y로 bounding box의 위치를 나타낸다. 이런 식으로 네트워크는 두 가지 출력값을 반환한다. 하나는 Class Score, 다른 하나는 입력 영상 내의 객체 위치의 bounding box의 좌표이다. 이 문제는 fully supervised setting 을 가정한다. 따라서 학습 이미지에는 카테고리 레이블과 해당 객체의 bounding box GT를 동시에 가지고 있어야 한다. 이 네트워크를 학습시킬 때는 loss가 두 개 존재하는데, 우선 Class scores를 예측하기 위한 Softmax loss가 있다. 그리고 Ground Truth Bbox와 예측한 Bbox 사이의 차이를 측정하는 Loss도 있다. L2 Loss로 BBox Loss를 가장 쉽게 디자인할 수 있다고 한다. 1이나 smooth L1을 사용해도 상관없다. 이 Loss들은 모두 예측한 Bbox와 GT Bbox 좌표 간의 차이에 대한 regression loss이다.

Bbox와 같이 이미지 내의 어떤 위치를 예측한다는 아이디어는 classification plus localization 문제 이외에도 아주 다양한 문제에도 적용해 볼 수 있는데, 그 중 하나가 human pose estimation이다. human pose estimation 문제 에서는 사람 이미지가 입력으로 들어간다. 출력은 이 사람의 각 관절의 위치로, 이 네트워크는 사람의 포즈를 예측한다. 즉, 이 사람의 팔다리가 어디에 있는지를 예측하는 것이다. 일반적으로 대부분은 사람들의 관절의 수는 같다. 모든 사람들이 그런 것은 아니겠지만 이 네트워크의 가정은 그렇다. 이런 문제를 풀기 위해서는 가령 일부 Data sets은 14개의 관절의 위치로 (사람의 발, 무릎, 엉덩이와 같이) 사람의 포즈를 정의한다. 이 네트워크의 입력은 사람 이미지이고, 네트워크의 출력은 각 관절에 해당하는 14개의 좌표 값이다. 예측된 14개의 점에 대해서 regression loss를 계산하고 backprop으로 학습을 시킨다. 가장 심플하게 L2 loss를 사용하기도 하고 또는 다양한 regression losses를 적용할 수 있다.
* "Regression Loss" 는 cross entropy나 softmax가 아닌 Losses를 의미하는데, L2, L1, smooth L1 loss 등이 있다.

object detection
Object Detection 문제에서도 고정된 카테고리가 존재한다. 예를 들어, 고양이, 개, 물고기 등 고정된 카테고리 갯수만 생각하는 형식이다. Object Detection의 task는 입력 이미지가 주어지면, 이미지에 나타나는 객체들의 Bbox와 해당하는
카테고리를 예측한다. classification plus localization와는 조금 다른데, 예측해야 하는 Bbox의 수가 입력 이미지에 따라 달라진다.

Object Detection이 Localization과는 다르게 객체의 수가 이미지마다 다르다. Object Detection 문제를 풀 때 예전부터 사람들이 많이 시도했던 방법은 sliding window이다. 앞서 Semantic segmentation에서 작은 영역으로 쪼갰던 아이디어와 비슷한 방법을 사용한다. Sliding window를 이용하려면 입력 이미지로부터 다양한 영역을 나눠서 처리해야되는데, 예를 들면, 이미지의 왼쪽 밑에서 작은 영역을 추출해서 그 작은 영역만 CNN의 입력으로 넣는다. 그러면 CNN이 작은 영역에 대해서 Classification을 수행하는 것이다. 밑에 예시를 보면 이 영역에는 개는 있고, 고양이는 없고, 배경도 아니다. 이때 가장 큰 문제는 어떻게 영역을 추출할지이다. 이미지에 Objects가 몇 개가 존재할지, 어디에 존재할지를 알 수가 없다. 그리고 크기가 어떨지도 알 수 없다. 그래서 이런식의 sliding window를 하려면 너무나 많은 경우의 수가 존재하게 되고, 작은 영역 하나 하나마다 거대한 CNN을 통과시키려면 이 때의 계산량은 어마어마해 다룰 수가 없을 것이다. 그래서 Object Detection 문제를 풀려고 brute force sliding window를 하는 일은 없다.

Sliding window 대신에 Region Proposals 이라는 방법이 있다. Region Proposal Network은 전통적인 신호처리
기법을 사용한다. Region Proposal Network는 Object가 있을법한 가령, 1000개의 Bbox를 제공해 준다. 이미지 내에서 객체가 있을법한 후보 Region Proposas을 찾아내는 다양한 방법(edges, etc)이 있겠지만, Region Proposal Network는 이미지 내에 뭉텅진(blobby) 곳들을 찾아내고, 이 지역들은 객체가 있을지도 모르는 후보 영역들이 된다. 이 알고리즘은 비교적 빠르게 동작한다. Region Proposal을 만들어낼 수 있는 방법에는 Selective Search가 있다. Selective Search은 밑에 슬라이드에 적힌 1000개가 아니라 2000개의 Region Proposal을 만들어 낸다. 우리가 CPU로 2초간 Selective Search를 돌리면 객체가 있을만한 2000개의 Region Proposal을 만들어난다. 우리는 이 Region Proposal Network를 이용해서 이미지 내의 모든 위치와 스케일을 전부 고려하는거 대신에, 우선 Region Proposal Networks를 적용하고 객체가 있을법한 Region Proposal 을 얻어낸다. 그리고 이 Region Proposals을 CNN의 입력으로 함으로써 계산량을 줄일 수 있다. 모든 위치와 스케일을 전부 고려하는 (brute force) 방법보다 낫다.

위에서 설명한 region proposal 아이디어는 몇년전에 나온 R-CNN이라는 논문에서 소개된다. 먼저, 이미지가 주어지면 Region Proposal을 얻기 위해 Region Proposal Network를 수행한다. Region Proposal은 Region of Interest (ROI) 라고도 한다. Selective Search를 통해 2000개의 ROI를 얻어낸다. 하지만 여기에서 각 ROI의 사이즈가 각양각색이라는 점이 문제가 될 수 있다. 그렇기 때문에 추출된 ROI로 CNN Classification을 수행하려면 FC-Layer 등으로 사용해 같은 입력사이즈로 맞춰줘야한다. 즉, Region proposals을 추출하면 CNN의 입력으로 사용하기 위해서는 동일한 고정된 크기로 변형시키는 과정을 먼저 거쳐야한다. R-CNN의 경우에는 ROI들의 최종 Classification에 SVM을 사용했다. RCNN은 BBox의 카테고리도 예측하지만, BBox를 보정해줄 수 있는 offset 값 4 개도 예측한다. 이를 Multi-task loss로 두고 한번에 학습하는 방식이다. 이 Task는 Fully Supervised 입니다. 따라서 학습데이터에는 이미지 내의 모든 객체에 대한 BBox가 있어야 한다.

R-CNN 프레임워크에는 많은 문제점들이 있다. R-CNN은 여전히 계산비용이 높다. R-CNN은 2000개의 Region proposals이 있고 각각이 독립적으로 CNN입력으로 들어갑니다. 이때 학습이 되지 않은 이 Region Proposal은
앞으로 문제가 될 소지가 많다. 또한, R-CNN은 학습과정 자체가 상당히 오래걸린다. 이미지당 2000개의 ROIs를 forward/backwrad pass를 수행한다. Fast R-CNN은 문제들을 상당부분 해결했다.

Fast R-CNN도 R-CNN과 시작은 같다. 하지만 Fast R-CNN에서는 각 ROI마다 각각 CNN을 수행하지 않고, 전체 이미지에 CNN을 수행한다. 그 결과 전체 이미지에 대한 고해상도 Feature Map을 얻을 수 있다. Fast R-CNN에는 여전히 Selective Search같은 방법으로 Region proposals을 계산한다. 이미지에서 ROI를 가져오는 형식이 아니라 CNN Feature map에 ROI를 Projection 시키고 전체 이미지가 아닌 Feature map에서 가져온다. 그러므로 CNN의 Feature를 여러 ROIs가 서로 공유할 수 있다. 그 다음 FC-Layer가 있는데, FC-Layer는 고정된 크기의 입력을 받기 떄문에 CNN Feature Map에서 가져온 ROI는 FC-Layer의 입력에 알맞게 크기를 조정해 줘야한다. 학습이 가능하도록 미분가능한 방법을 사용해야하는데, 이 방법이 바로 ROI pooling layer 이다. Feature Map에서 나온 ROI 크기를 조정하고 나면 FC-Layer의 입력으로 넣어서 Classification Score와 Linear Regression Offset을 계산한다. Fast R-CNN을 학습할 때는 두 Loss를 합쳐 Multi-task Loss로 Backprop를 진행한다.

Train time 에는 fast R-CNN이 10배 가량 더 빠르다. Faster R-CNN은 Feature map을 서로 공유하기 때문이다. Test time에는 fast R-CNN은 정말 빠르다. 이렇게 Fast R-CNN은 정말 빠르기 때문에 Region Proposal을 계산하는 시간이 대부분이게 된다. 2000개의 Region Proposal을 Selective Search로 계산하는데 2초 가량 걸린다. Region Proposals을 계산한 이후 CNN 을 거치는 과정은 모든 Region Proposals이 공유하기 때문에 1초도 안걸린다. 따라서 fast R-CNN은 Region Proposal을 계산하는 구간이 병목이다. 이 문제를 faster R-CNN이 해결해준다. Faster R-CNN은 네트워크가 region proposal 을 직접 만들 수 있다. Faster R-CNN은 별도의 Region proposal network가 존재해 RPN은 네트워크가 Feature Map을 가지고 Region proposals을 계산하도록 한다. RPN을 거쳐 Region Proposal을 예측하고나면 나머지 동작은 fast R-CNN과 동일하다. Conv Feature map에서 Region proposals을 뜯어내고 이들을 나머지 네트워크에 통과한 다음 multl-task loss를 이용해서 여러가지 Losses를 한번에 계산한다. Faster R-CNN은 4개의 Losses를 한번에 학습한다.

RPN에는 2가지 Losses가 있다. 한가지는 이곳에 객체가 있는지 없는지를 예측한다. 그리고 나머지 Loss는 예측한 BBox에 관한 것이다. Faster R-CNN의 최종단 에서도 두 개의 Losses가 존재한다. 하나는 Region Proposals의 Classification 을 결정하고 남은 하나는 BBox Regression으로 앞서 만든 Region Proposal을 보정해주는 역할을 한다.

지금까지 살펴본 내용은 R-CNN 패밀리에 관한 내용이었다. R은 " Region" 을 뜻한다. R-CNN 계열 네트워크들은 후보 ROIs 마다 독립적으로 연산을 수행한다. R-CNN 계열의 네트워크들을 region-based method 라고 한다. object detection에는 다른 방법도 존재한다. 그 중 하나가 YOLO로 You Only Look Once라는 뜻이다. 다른 하나는 SSD 인데, Single Shot Detection라는 뜻이다. 이들의 주요 아이디어는 각 Task를 따로 계산하지 말고 하나의 regression 문제로 풀어보자는 것이다.
입력 이미지가 있으면 이미지를 큼지막하게 나눈다. 예를들어, 밑에 예제를 보면 7x7 grid로 나눈다. 각 Grid Cell 내부에는 Base BBox가 존재한다. 밑에 예제의 경우에는 Base BBox가 세 가지 있다 (길쭉한놈 넓죽한놈 정사각형). 실제로는 세 개 이상 사용한다. 이제 grid cell에 대해서 BBoxes가 있고 이를 기반으로 예측을 수행할 것이다. 우선 BBox의 offset을 예측할 수 있다. 실제 위치가 되려면 base BBox를 얼만큼 옮겨야 하는지를 뜻한다. 그리고 각 BBox에 대해서 Classification scores를 계산한다. 이 BBox 안에 이 카테고리에 속한 객체가 존재할 가능성을 의미한다. 네트워크에 입력 이미지가 들어오면 7 x 7 Grid마다 (5B + C) 개의 tensor를 가진다. 여기에서 B는 base BBox의 offset (4개)과 confidence score(1개)로 구성된다. 그리고 C는 C개의 카테고리에 대한 Classification score이다.

Instance Segmentation
Instance segmentation는 지금까지 배운 것들의 종합 선물 세트 느낌이다. 입력 이미지가 주어지면 객체 별로 객체의
위치를 알아내야 한다는 점에서 Object Detection 문제와 유사하다. 하지만 객체별로 BBox를 예측하는 것이 아니라 객체 별 Segmentation Mask를 예측해야 한다 (이미지에서 각 객체에 해당하는 픽셀을 예측해야 하는 문제). Instance Segmentation은 Semantic Segmentation과 Object Detection을 더한 것이다. Object Detection 문제 처럼 객체별로 여러 객체를 찾고 각각을 구분해 줘야 한다. 가령 이미지 내에 두 마리의 개가 있으면 Instance segmentation은 이 두 마리를 구별해야 하고, 그리고 각 픽셀이 어떤 객체에 속하는지를 전부 다 결정해 줘야 한다. Instance Segmentation 문제를 푸는 아주 다양한 방법이 있지만 오늘 소개할 방법은 Mask R-CNN이라는 모델이다.

Mask R-CNN은 faster R-CNN과 유사하다. Mask R-CNN은 여러 스테이지를 거친다. 처음 입력 이미지가 CNN과 RPN을 거치는데, 여기까지는 Faster R-CNN과 유사하다. 그리고 Fast/Faster R-CNN에서 했던 것 처럼 특징 맵에서 RPN의 ROI만큼을 뜯어(project)낸다. 그 다음 단계는 Faster R-CNN에서 처럼 Classification/ BBox Regression을 하는 것이 아니라 각 BBox마다 Segmentation mask를 예측하도록 한다. RPN으로 뽑은 ROI 영역 내에서 각각 semantic segmentation을 수행한다. Feature Map으로부터 ROI Pooling(Align)을 수행하면 두 갈래로 나뉜다. 첫 번째 갈래에는 각 Region proposal이 어떤 카테고리에 속하는지 계산하고, Region Proposal의 좌표를 보정해주는 BBox Regression도 예측한다. 두 번째 갈래는 각 픽셀마다 객체인지 아닌지를 분류한다.

Mask R-CNN은 성능이 아주 뛰어나면서도 Faster R-CNN 프레임워크 기반으로 비교적 쉽게 구현할 수 있다.

'AI > CS231n' 카테고리의 다른 글
| [9강] CNN Architectures (0) | 2020.12.05 |
|---|---|
| [8강] Deep Learning Software (0) | 2020.11.28 |
| [6강] Training Neural Networks I (0) | 2020.11.14 |
| [5강] Convolutional Neural Networks (0) | 2020.11.07 |
| [4강] Introduction to Neural Networks (0) | 2020.10.31 |